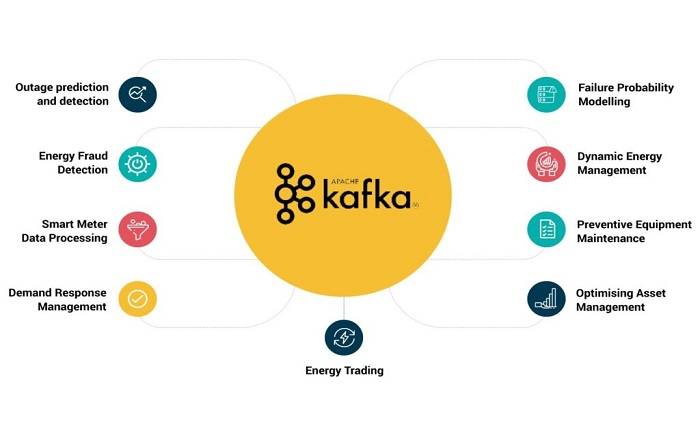
Apache Kafka is a distributed logging framework that organises data into topics. Kafka can read from a massive number of sources, including a grocery store’s transaction log. Kafka transforms the stream of information into topics that can be analyzed by anyone who needs to gain insight into a particular set of data. Unlike conventional databases, Kafka does not store the latest message until a user deletes it.
The Apache Kafka API consists of a producer and consumer API. A producer uses the Producer API to publish and subscribe to streams of records, and a consumer consumes the output stream. There is also a connector API that executes reusable producer and consumer APIs. Finally, there is an admin API to manage Kafka objects. Although there is no unified web interface for managing Kafka, there are several command-line tools that can be used to manage the service. These tools are located in the bin directory.
Apache Kafka is most commonly used in streaming data applications. Over 80% of Fortune 100 companies use it. Kafka scales like any other modern distributed system. It can support any number of applications that need access to data. Kafka’s design also makes it an ideal storage system. Data can be stored for as long as is needed, while most message queues remove messages once the consumer confirms receipt. Kafka is capable of handling stream processing and computes derived streams and datasets dynamically.
A key feature of Apache Kafka is its ability to scale partitions and topics across clusters. The system distributes the workload across multiple servers, allowing each server to focus on specific tasks. By using partitions, Apache Kafka can ensure fault-tolerant delivery of message streams. Apart from this, the Streams API enables developers to create Java applications that tap into the kafka stream. External stream processing systems can also be used to process Kafka message streams.
Apache Kafka is an open source distributed publish-subscribe messaging system that is optimized for ingesting streaming data. Streams are distributed and stored in a series of topics, with a timestamp added to each message. Kafka stores streams in order of their creation and process them in real time. It allows developers to create and manage applications based on data feeds and events. It also helps organizations build real-time event-stream processing pipelines.
The Apache Kafka API supports both producers and consumers. The producer can define a topic and partition and a consumer can read from it. The consumer does not have to define the partition, but it is helpful to do so as it allows for round-robin load balancing. This makes Apache Kafka a highly flexible platform for storing and analyzing data. However, it is not for everyone. It’s important to remember that Kafka is designed for tracking website activity and is designed to scale well.
Using Apache Kafka with a schema registry will prevent any unexpected messages from being sent by a consumer. Integration tests will help you understand the behavior of your application, and Kafka will ease the transition from an existing architecture to a new one. You can also use Kafka to join old elements with new ones. A good Kafka architecture makes it easy to scale, add new components, and join old ones.